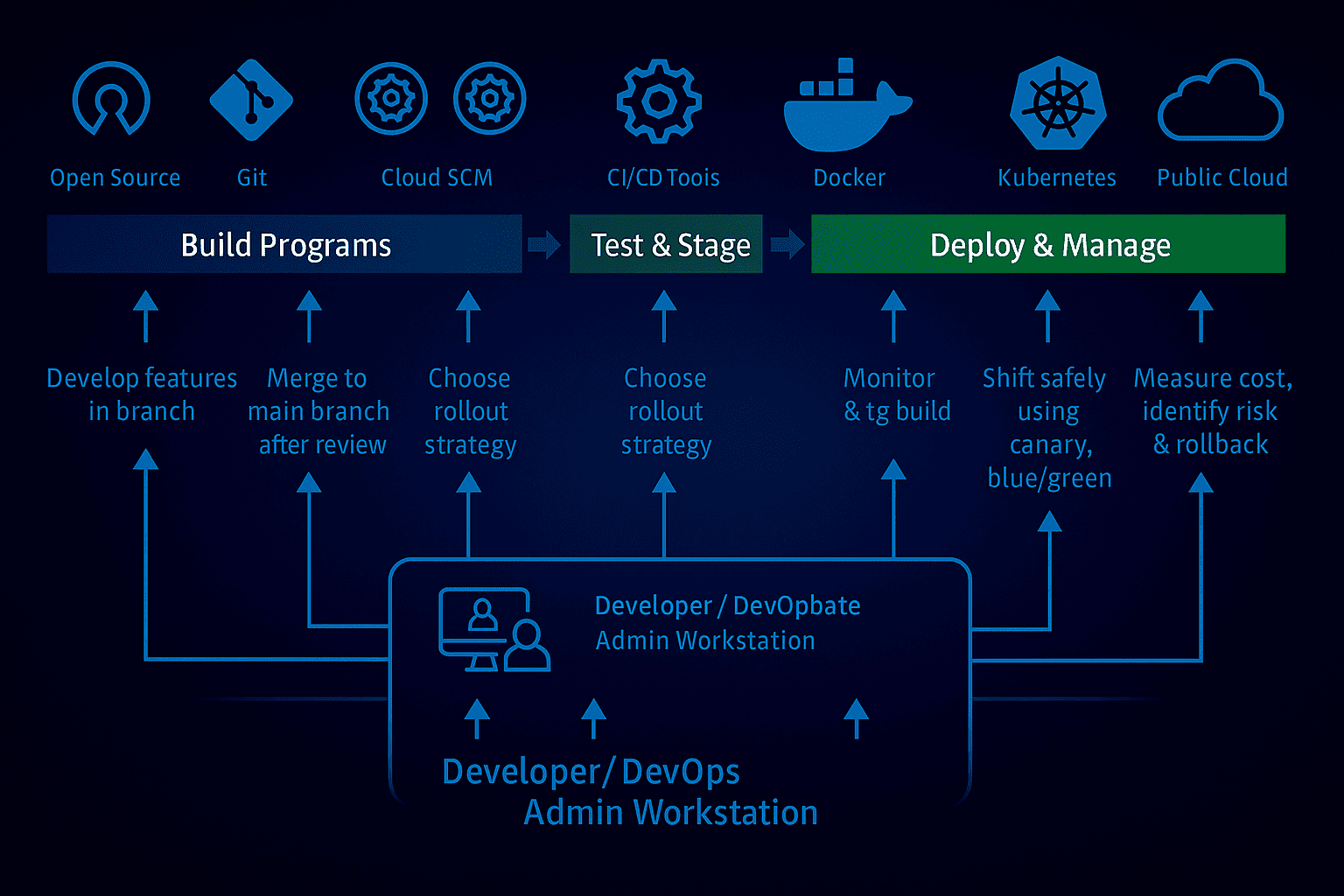
Why this guide? You???ll get clear explanations, production-ready checklists, copy-paste templates (YAML), and Kubernetes patterns???plus when to use Atmosly???s Pipeline Builder if you prefer visual pipelines without hand-rolling YAML.
Time to implement: 1???3 days for a basic CI pipeline; 1???2 weeks to add CD safeguards and Kubernetes strategies at scale.
Table of contents
CI pipeline: stages & templates
Quality & security gates (SLSA, SBOM, signing)
Performance & cost: caching, artifacts, runners
CI vs CD vs DevOps vs GitOps
CI (Continuous Integration): small, frequent merges; automated build + unit/integration tests; static analysis; fast feedback.
CD (Continuous Delivery/Deployment): automated packaging + release; approvals (delivery) or automatic release (deployment); rollback paths.
DevOps: culture + practices aligning dev & ops (obs, reliability, automation).
GitOps (subset of CD): desired cluster state is declared in Git; a controller (e.g., Argo CD) syncs changes into Kubernetes.
Want a side-by-side breakdown? See CI vs CD ??? Honest Comparison.
Core CI/CD architecture
A modern CI/CD pipeline architecture connects source control triggers to isolated runners/executors, builds and tests code, generates signed artifacts (container images, SBOMs, test reports), and promotes versions through environments with explicit gates before deployment. Post-release, observability and rollback playbooks protect reliability and shorten MTTR.
1) Source control & triggers (the pipeline starting point)
Your CI/CD pipeline should react predictably to repository events:
- Pull requests (PRs): run quick, deterministic checks???lint, unit tests, dependency scan???to give contributors sub-10-minute feedback.
- Merges to
main/trunk: run the full CI suite plus build artifacts needed for promotion. - Tags & releases (e.g.,
v1.6.0): kick off a release pipeline that signs images, attaches SBOM/provenance, and promotes through environments. - Schedules & path filters: nightly jobs for slow tests or SCA refresh; monorepo path filters ensure only changed services build.
Good defaults
- Trunk-based development, short-lived PRs.
- Required checks on PRs; protected branches; mandatory code reviews.
- Tag-driven release pipelines so production artifacts are always traceable.
2) Runners / executors (isolation, scale, and speed)
Where your CI jobs run materially affects reliability, security, and cost:
- Hosted runners: frictionless for public repos and simple networks.
- Self-hosted runners: needed for private networking (VPCs, databases), GPUs, or ARM builds; autoscale these on spot/preemptible capacity.
- Kubernetes runners (pod-per-job): each job runs in a short-lived pod with its own service account; great for bursty workloads and multi-tenant isolation.
Best practices
- Use ephemeral runners to avoid configuration drift and secret leakage.
- Pin base images and toolchain versions; treat the runner image as code.
- Pre-warm runners with common language layers to cut cold-start times.
3) Build stage (deterministic by design)
Reproducibility is a ranking factor for delivery quality???treat builds as pure functions:
- Pin base images and lockfiles (
package-lock.json,poetry.lock,go.sum,pom.xmlwith exact versions). - Embed build metadata (VCS SHA, build time) as labels.
- For containers, prefer multi-stage Dockerfiles with minimal final images; use
--provenancewhen supported.
Example image tagging
- Semantic tag:
app:1.6.0 - Immutable digest:
app@sha256:<digest> - Build tag:
app:<git-sha>
4) Test strategy (fast feedback first)
Adopt a test pyramid that keeps PR feedback fast while preserving depth:
- Unit tests (seconds): run on every PR; enforce coverage thresholds.
- Integration tests (minutes): exercise contracts (DB, cache, queue) with containers or ephemeral environments.
- Smoke/e2e (gated): run on staging or on nightly schedules to avoid blocking developer inner loops.
Flake control
- Quarantine flaky tests; add automatic retries with exponential backoff.
- Surface test timing to cut slowest 10% regularly.
5) Security scanning & supply-chain integrity
Integrate security at the same level as tests:
- SAST & linting: catch insecure patterns early.
- SCA (dependency scan): fail for critical CVEs; manage allowlists with expiry.
- Container/IaC scans: scan Dockerfiles, Kubernetes manifests, Helm charts, and Terraform.
- SBOMs: generate CycloneDX or SPDX for every build; publish alongside artifacts.
- Provenance & signing: create in-toto/SLSA attestations; sign container images (e.g., Cosign).
- Admission control: enforce at deploy time that only signed images with required attestations run.
6) Caching strategy (speed without stale results)
Caching is the highest-leverage accelerator for CI/CD pipeline performance:
- Language caches:
~/.npm,~/.cache/pip, Maven/Gradle caches keyed on lockfiles. - Container layer caching:
buildxcache-to/from registry or a shared cache volume. - Test result caching: reuse results when inputs/outputs are unchanged (where supported).
- Remote caches: for monorepos, centralize caches to avoid redundant downloads.
Guardrails
- Key caches on exact lockfiles; bust caches on lockfile changes.
- Set short TTLs on branch caches; longer TTLs on release branches.
7) Artifacts & registries (traceability and promotion)
Artifacts are the payloads your release pipeline promotes:
- What to publish: container image (digest), SBOM, test reports (JUnit), coverage summary, provenance attestations.
- Where to publish: an artifact repository (for reports) and an OCI registry (for images).
- Versioning: always reference production with an immutable digest, not mutable tags.
Retention
- PR artifacts: 3???7 days.
- Release artifacts: months or per compliance policy.
8) Environments & promotion gates (dev ??? staging ??? prod)
Promotion between environments is where CI becomes CD:
- Automated checks: post-deploy health checks, contract tests, synthetic user journeys, load tests where needed.
Policies & approvals:
- Continuous Delivery: manual approval gates in staging or before prod.
- Continuous Deployment: auto-promote when metrics and policy checks pass.
- Secrets & access: use external secret stores; rotate short-lived credentials; scope RBAC per environment.
Typical gate examples
- No critical vulnerabilities outstanding.
- Error rate and p95 latency within SLOs for N minutes.
- Required reviews complete; change ticket linked for audit.
9) Deployment strategies for Kubernetes (rolling, blue-green, canary)
Choose the right CI/CD pipeline deployment strategy per risk profile:
- Rolling update: default; replaces pods gradually; low overhead.
- Blue-Green: run two stacks (blue=current, green=new) and switch traffic at load balancer/ingress; instant rollback by flipping back; needs extra capacity.
- Canary / progressive delivery: start with a small slice (1% ??? 5% ??? 25% ??? 100%) and promote only if metrics stay healthy; automate pauses/rollbacks on SLO breach.
GitOps option
- Store desired state in Git; use Argo CD/Flux to reconcile clusters and prevent drift.
- Policy-as-code (OPA/Gatekeeper) enforces that only signed, attested images deploy.
Argo Rollouts canary (illustrative)
apiVersion: argoproj.io/v1alpha1 kind: Rollout metadata:
name: webapp spec:
replicas: 6
strategy:
canary:
steps:
- setWeight: 5
- pause: {duration: 2m}
- setWeight: 25
- pause: {duration: 5m}
- setWeight: 100
selector:
matchLabels: { app: webapp }
template:
metadata: { labels: { app: webapp } }
spec:
containers:
- name: web
image: registry.example.com/web@sha256:YOUR_DIGEST
ports: [{ containerPort: 8080 }]
10) Observability, DORA metrics & rollback (closing the loop)
Your pipeline is only as good as your feedback loops:
Observability: logs, metrics, traces; golden signals (latency, errors, saturation, traffic); release dashboards that tag deployments.
DORA metrics:
- Lead time for changes
- Deployment frequency
- Change failure rate
- MTTR (mean time to restore)
Track these per service; regressions should block further promotion until addressed.
Rollback playbooks: standardized, rehearsed procedures:
- Rolling back a Deployment (
kubectl rollout undo). - Blue-green traffic flip back to blue.
- Feature-flag kill switches and config rollbacks.
- Database migration backouts or forward-fix scripts.
Prefer visuals? Try Pipeline Builder to drag-and-drop this architecture, then export YAML.
CI pipeline: stages & templates
A practical CI pipeline for a Node.js service (adapt for any stack):
Minimal CI (build ??? test ??? scan ??? package)
# .github/workflows/ci.yml (example???adapt to any CI provider) name: ci on:
pull_request:
paths: ["service/**"]
push:
branches: ["main"]
jobs:
build_test_scan:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
- uses: actions/setup-node@v4
with: { node-version: "20" }
- name: Restore cache
uses: actions/cache@v4
with:
path: ~/.npm
key: npm-${{ hashFiles('**/package-lock.json') }}
- run: npm ci
- run: npm run lint && npm test -- --ci
- name: SCA scan (OSS deps)
run: npx trivy fs --quiet --exit-code 1 .
- name: Build image
run: |
docker build -t $REGISTRY/app:${{ github.sha }} .
docker save $REGISTRY/app:${{ github.sha }} -o image.tar
- name: SBOM
run: npx syft packages dir:. -o json > sbom.json
- name: Upload artifacts
uses: actions/upload-artifact@v4
with:
name: build_outputs
path: |
image.tar
sbom.json
Why this shape works
Caches speed up installs; failing fast on lint/tests reduces wasted compute.
Trivy/Syft add supply-chain visibility (SCA + SBOM).
Artifacts (image tar, SBOM) allow deterministic promotion to CD.
You can generate this pipeline in Atmosly???s UI and extend with templates for Python/Go/Java. See Features.
CD strategies for Kubernetes
1) Rolling update (default)
Replaces pods gradually; minimal extra infra; simplest.
Risk: bad changes roll to all pods unless stopped early.
2) Blue-Green
Two environments (blue=current, green=new).
Switch traffic at the load balancer/ingress; instant rollback by flipping back.
Needs extra capacity; great for high-risk releases.
3) Canary (progressive delivery)
Route 1% ??? 5% ??? 25% ??? 100% while watching SLOs.
Automate pauses/rollbacks if error rate/latency breaches thresholds.
Best practice with service mesh (e.g., Istio/Linkerd) or progressive controllers.
Argo Rollouts canary example
apiVersion: argoproj.io/v1alpha1 kind: Rollout metadata:
name: webapp spec:
replicas: 6
strategy:
canary:
steps:
- setWeight: 5
- pause: {duration: 2m}
- setWeight: 25
- pause: {duration: 5m}
- setWeight: 100
selector: { matchLabels: { app: webapp } }
template:
metadata: { labels: { app: webapp } }
spec:
containers:
- name: web
image: registry.example.com/web:${TAG}
ports: [{ containerPort: 8080 }]
GitOps with Argo CD
apiVersion: argoproj.io/v1alpha1 kind: Application metadata:
name: webapp spec:
project: default
source:
repoURL: https://github.com/acme/webapp-manifests
targetRevision: main
path: k8s/overlays/prod
destination:
server: https://kubernetes.default.svc
namespace: prod
syncPolicy:
automated: { prune: true, selfHeal: true }
syncOptions: ["CreateNamespace=true"]
Need a deeper dive? See CI/CD Pipeline and Continuous Deployment.
Quality & security gates (SLSA, SBOM, signing)
- Tests: unit, integration, smoke; enforce coverage thresholds on PRs.
- Security: SAST/DAST, dependency scanning (SCA), IaC scanning (K8s manifests/Terraform).
- Supply chain:
- SBOM per image (CycloneDX/SPDX).
- Image signing (Cosign) and admission policies (OPA/Gatekeeper/psp-equivalents) to only run signed images.
- Provenance via in-toto/SLSA???attest who/what built the artifact.
- Policy gates: block deploy if critical vulns, failing SLOs, or missing attestations.
Performance & cost: caching, artifacts, runners
Layered caching:
- Dedicate a step to warm language caches.
- Use buildx cache-to/from for Docker layers (or a shared registry cache).
Artifacts & retention:
- Retain only what downstream needs (image digest/SBOM/test reports).
- Apply TTLs by branch (short for PRs, longer for releases).
Runners:
- Use autoscaled ephemeral runners on spot instances; pin CPU/RAM to job profile.
- For monorepos, add path filters to avoid building unrelated services.
Concurrency & flake control:
- Limit concurrent prod deploys; add retries with backoff for flaky e2e tests; quarantine flaky tests with labels.
Runbooks & checklists
Pre-merge (CI) checklist
- Lint + unit tests pass (???80% coverage target)
- Vulnerability scan: no critical SCA/SAST issues
- Image builds reproducibly; SBOM attached
- CI time ??? 10 min for typical PR (budget via caching/parallelism)
Pre-deploy (CD) checklist
- Integration/e2e tests pass in staging
- Migration plan + rollback plan attached to the PR
- Canary guardrails configured (error rate, p95 latency, saturation)
- Feature flags ready to disable risky code paths
Rollback runbook (Kubernetes)
- Freeze deploys; page owner.
- Flip traffic: set previous stable ReplicaSet (blue) to 100% or
kubectl rollout undo deploy/webapp. - Verify: error rate, latency, saturation normalized.
- Postmortem: capture logs, diff SBOMs, attach Grafana panels, open a fix-forward PR.





